I looked through the source code of fasm and thought that it might be possible to try to arrange in the past so that the author of the fasm would meet with the great Austalian humanist and show him the source code? Obviously, after this meeting, another shallow grave will appear in the Australian bush, and you will now be the elite programmer on MASM. What do you think?
Last edited: 08.05.2019 by KyberMax, read: 5182 times
I remembered that I have several small programs written without links to libraries. Here is one of them, written back in 2016. It shows the obvious superiority of using MASM over other Assemblers when creating programs with Unicode support. When non-MASM programmers use macros, strings from resources or stupidly manually translate Unicode letters into codes, modest MASM programmers simply write the source directly in Unicode.
Something like that, for example (at the same time, we will check how this forum supports Unicode):
Using UTF-16 is not a good idea IMHO. In fact, there are two more or less reasonable alternatives: UTF-8 is you want to be small and ANSI compatible and UTF-32 if you want to be fast. FreshLib uses UTF-8.
Last edited: 05.05.2019 by KyberMax, read: 5166 times
Unfortunately, Micro$oft did not ask your HO and made this encoding as Unicode in Windows. However, as you might see, I use UCS-2 encoding in this program, not UTF-16, i.e. without surrogates, otherwise setTextArrW would look a bit more complicated.
I know. That is why I use batch file instead of any IDE, because they are convenient and very easy to modify for anything. For example, I used this batch file as IDE when developing that program:
@echo off
set PROJ=HelloUcW
call Settings.bat
:LOOP
@echo Project: %PROJ%
@echo [A]ssemble [R]un [D]elTrash [L]ist:%LST% [Q]uit
@choice /C:ARDLQ /N >nul
if errorlevel 5 goto QUIT
if errorlevel 4 goto SWLIST
if errorlevel 3 goto DELTR
if errorlevel 2 goto RUN
\Masm32\bin\nmake.exe /f %PROJ%.mak
goto LOOP
:RUN
%PROJ%
goto LOOP
:DELTR
call DelTrash.bat
goto LOOP
:SWLIST
if %LST%==Y goto LISTOFF
set LST=Y
goto SAVEVARS
:LISTOFF
call DelLists.bat
set LST=N
:SAVEVARS
@echo : Settings for MakeIt.bat>Settings.bat
@echo set LST=%LST%>>Settings.bat
goto LOOP
:QUIT
Last edited: 06.05.2019 by KyberMax, read: 5158 times
Well, since you're writing in Asm under Linux, then why don't you translate Fresh to UTF-16 to bring the resentment of red-eyed penguins to the limit? In addition, this encoding is almost entirely fixed-width characters (excluding the 2K range), which will be a small but pleasant bonus to the basic motivation.
Well, "almost" is not enough. If I need fixed-width encoding, I will use UTF-32. But for now, I am considering the small size and ANSI compatibility more important, so I am using UTF-8. It is really not so hard for processing and the variable width is a performance problem very rarely.
On the other hand UTF-16 is the most inconvenient way to encode UNICODE. Why I should use it if I am not forced by the OS API?
Well, emoticons and Egyptian hieroglyphs can be ignored before the introduction of UTF-32 IMHO.
I would definitely use this encoding precisely because it is about the same as using Asm in Linux.
Actually, I slightly exaggerated the possibilities of MASM (you initially knew about this, of course). MASM, of course, does not support Unicode - I just use a converter.
But as a result, there was an interesting opportunity to use Unicode and ASCII encoding simultaneously. In general, with this converter any, even the most ancient mammoth shit, can work with Unicode (now UCS-2). The only requirement: Asm should understand the text in single quotes as strings (strings in double quotes are translated by converter into hex words).
Today I checked the ability to display surrogate pairs and found that the setTxtArrW procedure works correctly, because lstrlenW considers surrogate pairs as two words, not one character. So UTF-16 is supported.
Another thing is that even on Windows 7 x64 Unicode font in the field of surrogate pairs I did not find any characters at all.
Last edited: 16.05.2019 by KyberMax, read: 5121 times
In addition to the previous post: it is interesting that the ranges of the first and second surrogates do not match. Therefore, it is possible to make an incorrect pair and then this pair will be displayed as two non-printable characters (as two squares). If the pair is made correctly, then it is displayed as one square (no symbols were found in the surrogate range). That is, the developers have narrowed the maximum possible range of 4 million to 1 million characters.
If someone gave the alphabet to the Chinese, Koreans and Japanese before the introduction of Unicode, then UTF-16 would be enough without any surrogates.
By the way, about the missed opportunities: are you still a fasm programmer, not nasm one?
Last edited: 29.05.2019 by KyberMax, read: 5083 times
I don’t know if you could compile the file without all the project files, but I didn’t publish the whole project, because I have long wanted to slightly expand the capabilities of the converter and used this opportunity to return to the development. As a goal, I chose one of the most monstrous assemblers - Atmel Avrasm, just look at its C-like syntax
As in C, strings in this asm can only be in double quotes, and characters only in single quotes. So I had to enter the key to convert single quotes into double quotes.
Among other things, the example demonstrates how to place double quotes in strings (neither the Asm- nor the C-syntax is supported by this assembler). Hexadecimal numbers are defined in it using the prefixes 0x or $, so I had to enter the prefix definition key. In addition, fixed a bug that did not allow to specify any extension of the output file.
By the way, I had to modify the batch file to build the executable, because in the modern Masm32 package, there is no h2inc.exe utility, so you have to search it on the web or use h2incX.exe, developed by Japheth, instead. It can be downloaded from the developers site of a very cool Uasm assembler, the possibility of choosing which for assembly I also included in this batch file.
And of course in the Masm32 package there is no converter itself - this brilliant crutch, when meeting with the incredible capabilities of which the whistle of the great Australian humanist burnt so much that all his professionalism instantly fell off of him and he began bravely to spit shit in the back of the cyborg.
Last edited: 29.05.2019 by johnfound, read: 5077 times
Well, I can't see C-likeness in the avrasm syntax. BTW, I am using AVRA which is (almost) compatible:
AVRA: advanced AVR macro assembler Version 1.3.0 Build 1 (8 May 2010)
Copyright (C) 1998-2010. Check out README file for more info
AVRA is an open source assembler for Atmel AVR microcontroller family
It can be used as a replacement of 'AVRASM32.EXE' the original assembler
shipped with AVR Studio. We do not guarantee full compatibility for avra.
AVRA comes with NO WARRANTY, to the extent permitted by law.
You may redistribute copies of avra under the terms
of the GNU General Public License.
For more information about these matters, see the files named COPYING.
Last edited: 31.05.2019 by KyberMax, read: 5071 times
Description of strings and single characters: strings in double quotes only, single characters in single quotes only. In assembler free use of quotes.
C-style escape sequences \n \r, etc.
Using the prefixes 0x 0b instead of the suffixes h b.
Ability to use C-style comments.
C-style operators !~ << >> || == != etc.
Yes, I know this assembler and in my development there is an opportunity to quickly change the assembler. The main difference is that Avrasm uses a 64-bit internal representation of variables, and avra uses 32-bit and it is easier to get overflow in calculations (apparently, therefore, avra has no .DQ directive). But avra has more advanced macros (in the C-style, by the way).
Perhaps yesterday it made sense to place here not only the result of the converter, but also the listing (after all, the chips are outdated and not everyone has these assemblers).
So, Unicode on Atmel AVR microcontrollers... How do you like this, Elon Musk?
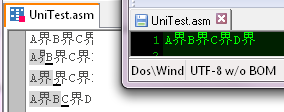
So you say: "why does this cyborg use UTF-16 when everything works with UTF-8?". Well, you do not say it - you think. So I decided to check how well it works, and here is the result:
For the test, the simplest UTF-8 string was used, consisting of alternating consecutive Latin characters and one Chinese hieroglyph (to make it easier to orientate). On the right side of the picture, this string is displayed in the NotePad++ editor, and on the left in the Fresh IDE. The strings, starting with the second line, demonstrate consistent characters highlighting (the picture is maked with the Paint editor).
Yes of course, all this can be fixed, but this is a good example of the fact that simpler code is better because more reliable (and faster, by the way, which is important for microcontrollers). That is why I wrote this simple converter - so that I could use the true Unicode, and not bother with this crappy variable-length characters, this ugly crutch, invented by lazy C-developers. Ideally, they should have added the ability for the compiler to use the source code in Unicode UCS-2 (enter a special option for this), but instead they invented another type of Unicode. As a result, they facilitated the work of the compiler and turned the simplest programmer's work with strings into an intricate quest.
Well, I can't see any relation between Unicode encoding and the buggy display of the Chinese hieroglyphs in Fresh IDE. And a proof of this is that the Fresh IDE v2.x editor uses exactly UCS-2 encoding. Because it is Windows API implementation.
Fresh v3.x will use another editor that uses UTF-8. But I am not sure it will display the hieroglyphs properly, not because of the encoding, but simply because there is no monospaced fonts containing Chinese hieroglyphs.
So, the hieroglyphs you see in Notepad++ and Fresh IDE are from substitution font and the sizes of the characters are different. Fresh IDE editor always expect the width of the characters to be the same. You can see the same effect if set in the editor some proportional font. In this case even latin characters will be displayed wrong.
And in reverse - if you have a monospaced font containing the needed characters, everything will work ok.
Last edited: 03.06.2019 by KyberMax, read: 5035 times
Yes, you're right - suddenly the thing is in different widths of characters. For verification, I even downloaded and installed the font of the last version of the Unifont. But even in it, the Chinese and other hieroglyphs have different widths, although it is declared as monospaced. You will have to take into account this feature for the correct display of all characters. Obviously, NotePad++ does not rely on the same width of characters when calculating the length of the string graphics; it sums the width of each character separately.
However, all this does not affect my opinion on UTF-8 encoding.